Tokenization
- Canonical letter (amino acid, nucleic acid) to token
- Small alphabet
- Long sequences
- Positions and length of two sequences is preserved.
- Natural language tokenizers
- Representing additional information
Multimodality
- Geometric Attention Autoencoder (ESM 3)
- “Structural” tokenization
- Atomic tokens
- If an amino acid is a word, an atom might be a letter.
- On the atomic level there usually is not a sequence without forks and loops.
- AlphaFold 3 can be thought of as a multi-modal model.
- It uses sequences as input and produces point clouds (atom coordinates) as output.
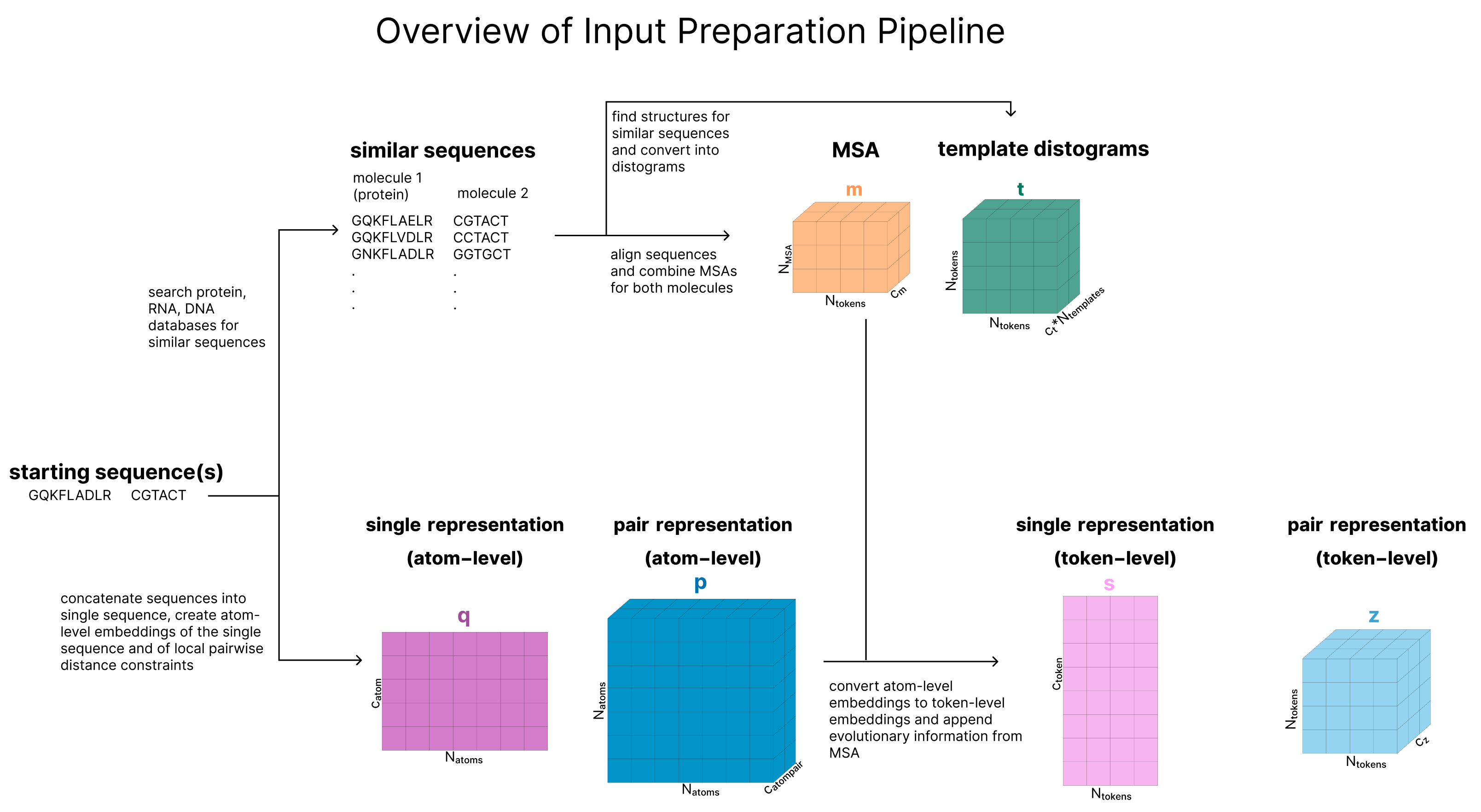
Conclusions so far
- Data driven tokenizers improve results for tasks, where “per amino acid reasoning” not required.
- Where per token information is enriched with additional context, no compression is used currently.
- There might be some future research in this area.